デジタルジャーナリズムのためのTow Centerが実施した新しい研究は、すでに既知の問題に新たな光を投げかけていますが、技術的な進歩にもかかわらず持続しているようです。生成的人工知能に基づくチャットボットの信頼性。コロンビアジャーナリズムレビューに掲載されたこの研究では、ジャーナリスティックな記事に基づいていくつかの検索エンジンの回答を200のクエリに分析し、極度の安全性を備えた誤った情報を提供するという驚くべき傾向を明らかにしました。
この研究は、ジャーナリスティックな質問に対する正確な回答を提供できるチャットボットの量を理解しようとしました。私たちは事実から始めました。人工知能は日常生活にますます存在し、あらゆるトピックに関する情報を取得するために使用されています。しかし、これらのツールによって提供される答えをどれだけ信頼できますか?
研究の結果
研究結果は心配でした。たとえば、ChatGpt検索は、200の質問すべてに答えるための唯一のツールでしたが、回答の28%のみが完全に正確でした、57%には完全に誤った情報が含まれていました。このデータは、以前に既に観察されたこと、つまり、特定の情報がない質問にも安全に答えるChatGptの傾向を確認します。
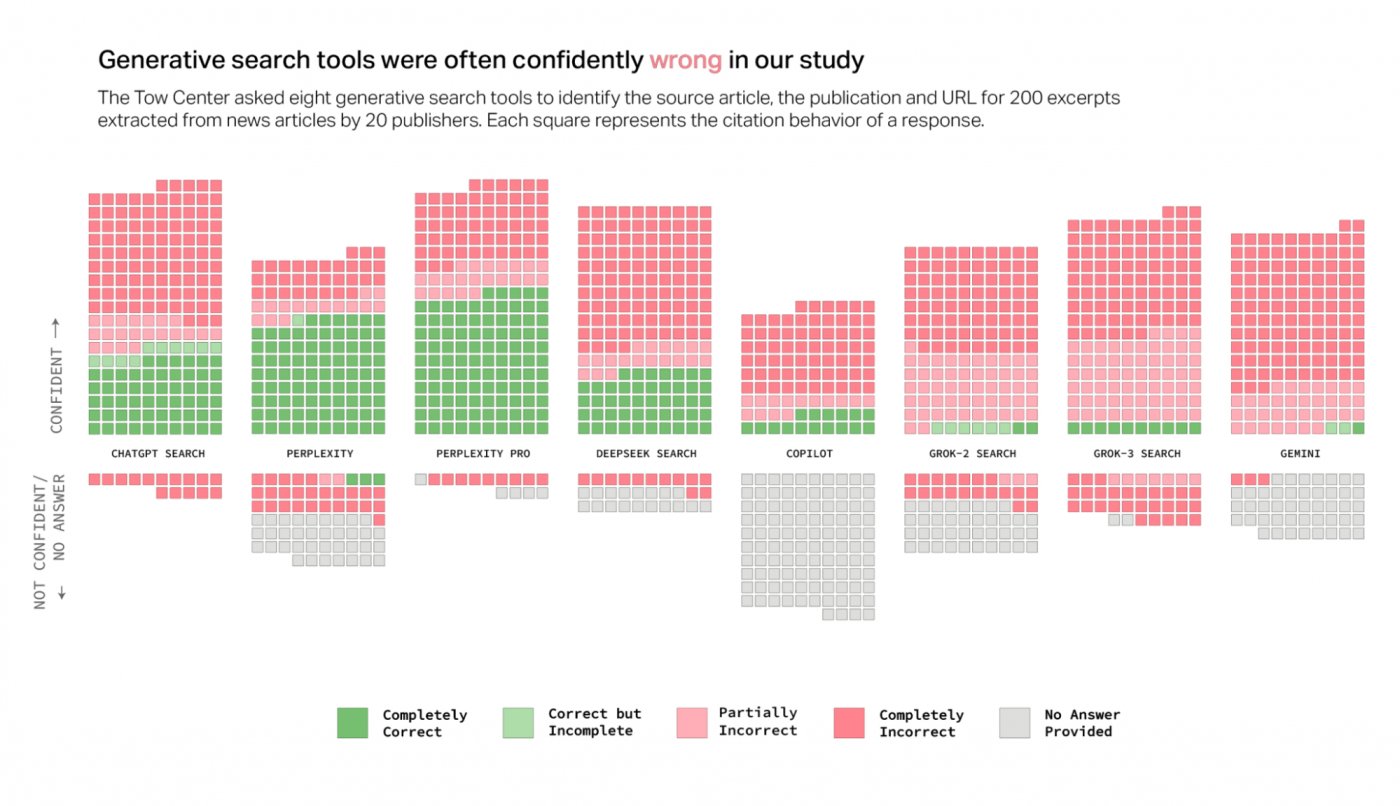
しかし、ギャップを表示するのはChatGpt検索だけではありません。 GROK AI XSの両方のバージョンはパフォーマンスの低下を示し、GROK-3は不正確な反応の94%に達しました。 Microsoft Copilotでさえ輝いておらず、200のうち104に応答することを拒否し、提供された回答で約70%の精度率を提供します。
状況をさらに逆説的にするのは、このとらえどころのないことに関する製造会社の透明性の欠如です。奇妙なことに、Perplexity ProやGrok-3の検索などの有料バージョンは信頼性が低いようです:「「1か月あたり20ドル)やGrok 3(月額40ドル)などのプレミアムモデルは、無料のカウンターパーティよりも信頼性が高い」と想定することができます。高い "。
著者によると、この矛盾は、質問に直接答えることを拒否するのではなく、決定的な、しかし誤った答えを提供する傾向に由来しています。
そして、あなた、あなたはどう思いますか?チャットボットで同様の経験をしましたか?コメントであなたの意見を共有してください。その間iPhoneを組み立てる会社は、彼のIAの1つを開発しました:FoxconnのFoxbrainが到着しました。





