OpenAI の ChatGPT や Google の Gemini など、新しく強力ないわゆる人工知能モデルの出現により、その実際の有効性について一連の疑問が生じています。実際、これらのテクノロジーを開発する企業は、ユーザーの信頼に依存して、独立した制御を行わずにモデルのパフォーマンスに関するデータを提供することがよくあります。
米国の研究機関である Epoch AI は、このシナリオを変えることを目指しています。 AI 研究者のハイメ・セビリア氏が率いる Epoch AI は、AI ベンチマーク ハブ、AI モデルの機能の公平かつ透明な評価を提供するオンライン プラットフォームです。しかし、AI ベンチマーク ハブはどのように機能するのでしょうか?
L'l'AI ベンチマーク ハブ
AI ベンチマーク ハブは、特定のベンチマークを使用して、さまざまな分野で AI モデルの機能をテストします。現在、プラットフォームは 2 つの主要なベンチマークに重点を置いています。
- GPQA ダイヤモンド: 複雑な科学的質問に答える AI モデルの能力を評価する、生物学、物理学、化学の大学レベルの問題を含む多肢選択テスト。
- 数学レベル 5: 複雑な数学的問題を解決する AI モデルの能力を測定する、さまざまなコンテストからの高レベルの数学的問題のセット。
テスト結果はインタラクティブなグラフを通じて表示され、研究者、開発者、ユーザーが簡単にアクセスできます。この透明性の高いアプローチにより、製造会社の宣言を超えて、さまざまなモデルのパフォーマンスを客観的な方法で比較することができます。
最高のAIとは何でしょうか?
Epoch AI によって実施されたテストでは、すでにいくつかの興味深い観察結果が得られています。たとえば、OpenAI の o1-preview モデルは、最も先進的なモデルの 1 つであるにもかかわらず、GPQA ダイヤモンドで人間の専門家のスコアと同等のスコアを獲得しましたが、同社が宣言したスコアよりも低かったです。

しかし、Math Level 5 ベンチマークでは、OpenAI の o1-mini がその高い数学的能力で際立っており、Google の o1-preview と Gemini 1.5 Pro がそれに続きました。 4位となったAlibabaのQwen2.5-72Bは驚くべき結果を達成した。
Epoch AIも分析していますダウンロード可能なモデルとダウンロードできないモデルのパフォーマンスの違い、ラマ 3.1-405B が率いる後者がどのように追いつくのに苦労しているかを強調しています。
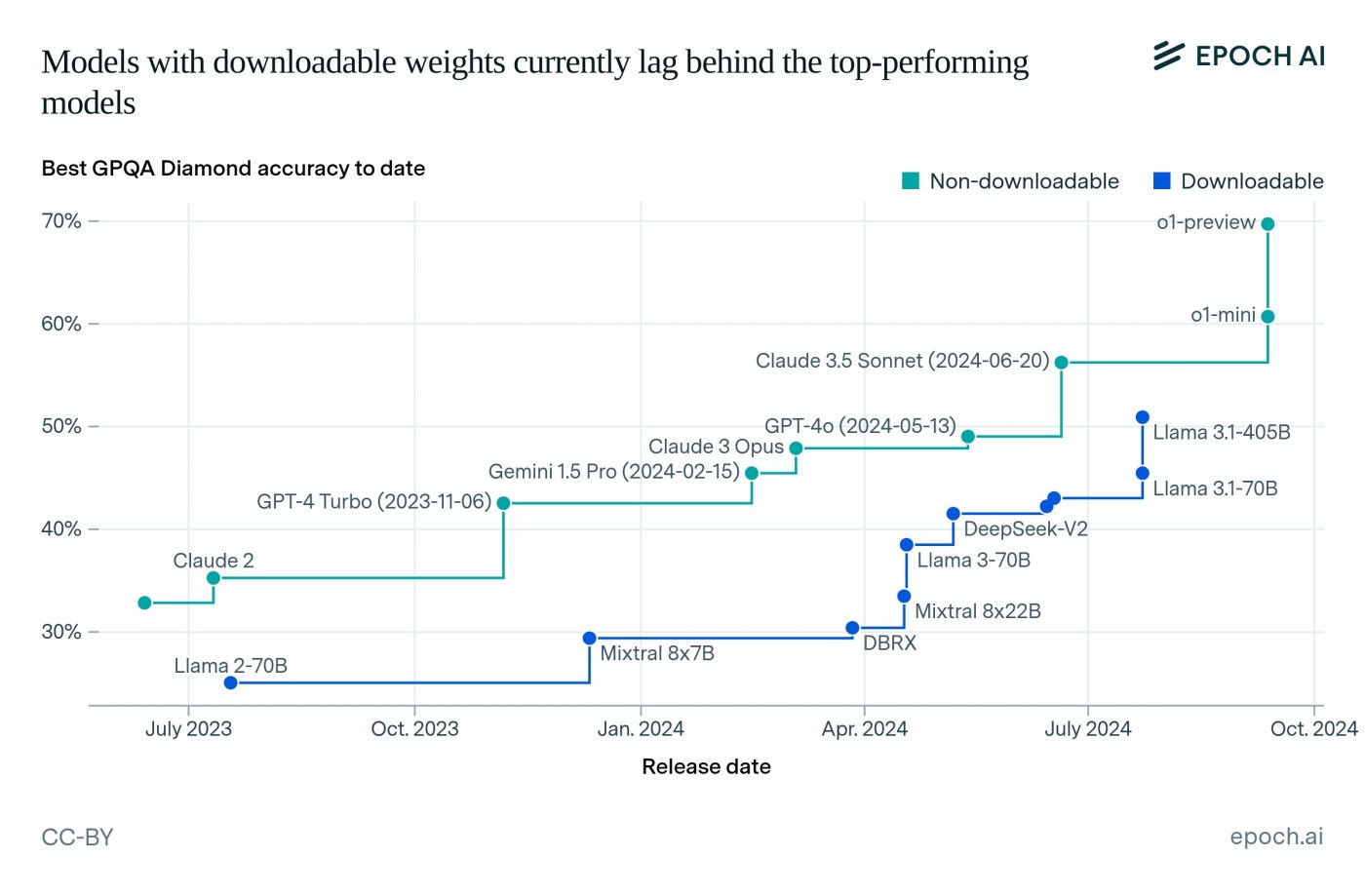
将来的には、Epoch AI は AI ベンチマーク ハブを拡張して、新しいベンチマークを追加し、より多くのモデルをテストする予定です。これにより、AI の状況をさらに完全かつ正確に把握できるようになり、ますます高度で信頼性の高いテクノロジーの開発が促進されます。
この取り組みについてどう思いますか? AI の評価に独立した機関があることは有益だと思いますか?以下のコメント欄であなたの意見を教えてください。さて、AIといえば、Googleは現在、AIが生成したチェスのサイトを開設し、新しいGeminiボットの開発に取り組んでいる。





